

Dan Shick
24. June 2026
The world of Linked Open Data grows larger every day thanks to inspiring and interesting open-data projects. Recently we chatted with Tim Wittenborg about just such a project — the WissKomm Wiki, which he initiated at the Leibniz Information Center for Science and Technology in TIB Hannover.
Please introduce the WissKomm Wiki project. What motivated the idea of building an open knowledge base for science communication content like videos and podcasts?
The science journalist Mai Thi Nguyen-Kim once said, “When our arguments are based on our smallest common reality, we’re not just arguing in place — we move forward.”
A few colleagues and I liked this statement and went looking for this “smallest common reality”. We agreed that Wikipedia is arguably the best fit, the best approximation of a common ground truth. We did extensive research into science, particularly scientific articles and the Open Research Knowledge Graph (ORKG), a platform dedicated to making knowledge from scientific papers accessible to machines. Ideally, this machine-accessible knowledge graph based upon all scholarly knowledge ever externalized should be a fantastic ground truth — but would it constitute that smallest common reality?
We started to wonder why society still sees so much discontent despite having Wikipedia, and if even a perfect ORKG might fail to fill that gap. We came to the conclusion that another layer is required: a layer of science communication, closer to the means of everyday information exchange, such as videos and podcasts.
That’s how the WissKomm Wiki idea was born, refined over the past four years to the project we have today.
WissKomm Wiki places a Wikibase instance at the center of its infrastructure. What made Wikibase the right choice for organizing and connecting this type of data?
When a colleague told me about wikibase.cloud, I was amazed that one could have “one’s own Wikidata”. We quickly learned just how attainable this was, and we learned a great deal more over the course of a master’s thesis supervision, a published paper, and two MediaWiki Users & Developers conferences (one of which I hosted as general chair).
In short, Wikibase has it all. It’s complex enough to be meaningful, with qualifiers and references and so forth, but simple enough to be usable and understandable for everyday users. It doesn’t use all the power of semantic technology — it doesn’t even use classes in the regular sense — but, by this simplification, Wikibase cuts out many of the reasons for scratching our heads that we’ve encountered over the years.
The KISS principle — “keep it simple, stupid” — was one of my favorite principles they taught us in uni. Now, a decade into knowledge management, I can truly appreciate its meaning. From the TIB Open Science Lab to project and charity members, we all think that Wikibase hits that sweet spot of simplicity.

How do you envision the role of Wikibase within the overall platform? What kinds of questions or use cases should the knowledge graph make possible?
Wikibase represents the main source of truth: the center node, the first access point, the default. The only reason not to put something into our Wikibase instance is if it simply can’t be put there, such as long texts or images.
Wikibase can provide answers to nested questions, such as “What videos on climate science were created with the help of at least two people bearing a degree in climate science?”, or simply “video X mentions paper Y”, which allows querying for every video that ever mentions a particular paper.
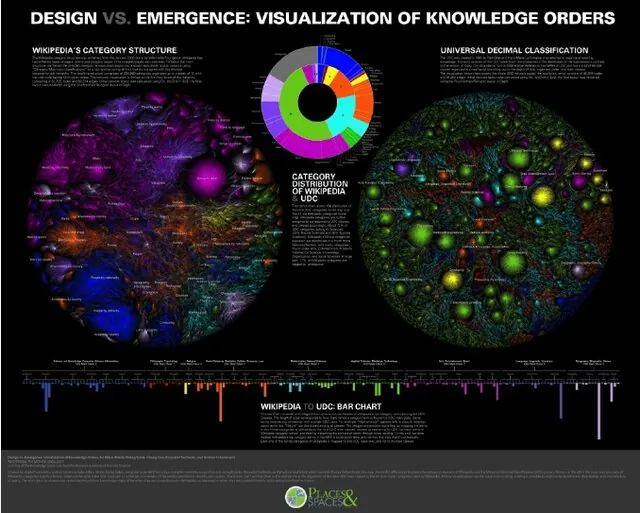
The main benefit of Wikibase is that you don’t need to think too much about what the question will be. The beautiful visualization below, “Design vs. Emergence: Visualization of Knowledge Orders“, captures how structure emerged in Wikipedia. [Ed. note: see also Knowledge Maps of the UDC] We expect the same thing to happen on our wiki: It began with some seeding, some initial thoughts and application of lessons learned, but we expect mainly community-driven growth.
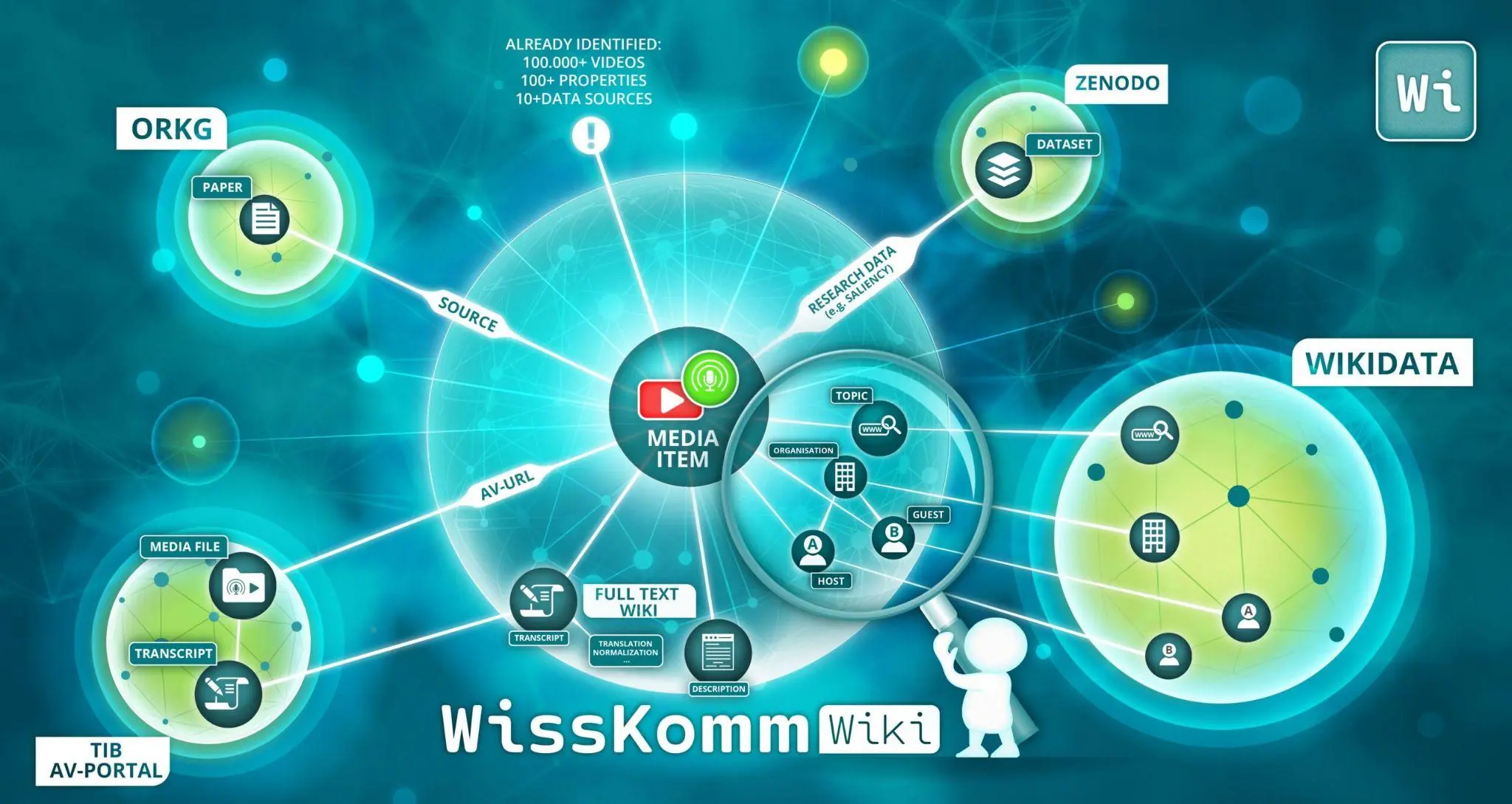
Could you describe the basic data model you are developing in Wikibase? For example, what kinds of entities and relationships are most important for representing science communication content?
The three simplest classes are video, podcast, and scholarly article. Each is a knowledge artifact and can be further described by who created it (author, editor), what information it contains (topic, statement), and for whom they are made (target audience, language level, complexity level). In this we build on existing methodologies.
For one, we derive properties from existing research, such as Wittenborg et al. 2026 (PDF). Based on this research, we already have over 1600 properties in the instance that paper uses. Given that Wikidata has around 12,000, our own catalogue will probably grow as well, and this growth, much like that of Wikidata, will be coordinated using property proposals. Wikibase’s combination of flexibility in nodes (subjects & objects) with its more rigid edges (properties) will make the resulting knowledge graph easier to work with and scale for everyone.
Wikibase makes it possible to link data to other knowledge graphs. Do you plan to connect WissKomm Wiki to external resources such as Wikidata or other open datasets, and if so, how?
We founded the charity behind the WissKomm Wiki (BorgNetzWerk e.V., Association for the Networking of Free Knowledge) for exactly this purpose. We take Wikimedia Deutschland e.V. as an example and place our focus on audio-visual science communication content.
The main idea is that plenty of great resources already exist that probably hold the answers to most questions. Our goal is to connect these resources, just like Wikidata and Wikisource, but applied to content beyond the license and scope limitations of these mainline Wikiverse projects. We want to connect to the ecosystem of Linked Open Data, taking Mimotext as an example.
Connecting to Wikidata in particular is vital as the central general knowledge node, but also to the ORKG, where we will have the scholarly articles described. A system that tries to do everything can’t do everything right. We want to focus on annotating videos and podcasts; we’re happy to outsource everything beyond that scope that we possibly can to a more dedicated knowledge infrastructure.
We can build the kind of bottom-up, intrinsic motivation for a broad community to come together and curate what they already enjoy.Tim Wittenborg
How will contributors interact with the Wikibase instance? Will there be workflows or tools that help researchers and community members add or curate data?
Users will always be able to log in and edit, just like Wikidata. We are also working on simplified and more accessible workflows. Like StreetComplete and the Wikidata Card Game Generator, we want to invite people to playfully interact with the information and contribute where it applies to their daily life. One of our long-term goals would be a commonly used browser plugin: While you’re browsing, a single click should allow you to bring any media onto the WissKomm Wiki’s radar, just like Zotero.
The project emphasizes the FAIR data principles. How does WissKomm Wiki aim to make science communication content more findable, accessible, interoperable, and reusable?
“More” is the key to this answer. People are already finding these videos — but it’s by luck or accident, not necessarily when they are in need of exactly that kind of video. People already have access to videos — but not when they are taken down, modified or paywalled. People already have transcripts — just none they can verify, annotate, translate or use in search. And people already can and do reuse videos — but their licensing remains confusing to many.
The WissKomm Wiki probably won’t revolutionize this state of affairs overnight, but we do think it will significantly boost curated, FAIR knowledge in our particular domain. The dissertation I’m currently writing on this exact topic tells me there’s impressive potential for each of these building blocks. How nice would it be to collect all your videos and podcasts in one interface, filter them, and search their transcripts?
WissKomm Wiki is not only a technical platform but also a community effort. Who do you hope will contribute to the project, and how do you plan to involve them?
Anyone who already interacts with videos and podcasts and wants a more informed way to do so. That could be someone who wants their favorite podcast highlighted, or wants to learn how their most-watched video channel evolved, or who simply wants to know their favorite creator’s most frequently used word. Motivations abound; all we need to do is connect to the community. A few examples can already be found on our project website.
By reaching out to individuals and creators, researchers and institutions, we feel that we can build the kind of bottom-up, intrinsic motivation for a broad community to come together and curate what they already enjoy. This approach has been working for the gaming community for years, and the same goes for movies. We see no reason why it wouldn’t work for WissKomm Wiki.
What kinds of benefits do you hope the WissKomm Wiki will bring to the science communication community, such as researchers, communicators, and audiences?
In short: FAIR data.
For researchers, we probably don’t need to explain what that means: data I can use however I desire to answer the many questions I may want to ask; domain-independent, crowdsourced, interoperable meta-reviews. As with the Open Research Knowledge Graph and Wikidata, the potential is already wonderful.
For audiences, the answer is actually similar. You can ask your own questions, ones that are immediately useful to you — “I want a video/podcast that meets my expectations” — and WissKomm Wiki will give you the tools to specify those expectations, so that the machine behind your search bar can understand them.
For communicators, we provide a wider variety of benefits: highlighting and verification for your content, beneficial to those interested in science communication, as well as the aforementioned benefits to their community, since a happy community benefits communicators as well. Crowdsourced transcriptions and potentially translations would be a bonus, but we’ll have to see exactly how that picks up adoption and momentum.
Technically, we’re set. Community-wise, we’re looking at a very promising start. All we need now is you!
Tim Wittenborg is the initiator of the WissKomm Wiki and founder of the charity BorgNetzWerk – Gesellschaft zur Vernetzung Freien Wissens e.V. After finishing his master’s degree in engineering and computer science at Paderborn, he started his PhD in Data Science and Digital Libraries at Hannover in 2023. There he works at the Leibniz Joint Lab of the L3S Research Center of the LUH and the TIB – Leibniz Information Centre for Science and Technology and University Library.
His work, thesis, and personal passion revolve around knowledge infrastructures and making the scientific method behind it transparent, understandable, and accessible to a broad audience.



