
Neues Wikidata-Tool
Sprachenlernen mit lexikografischen Daten: Die Wikidata-basierte App Scribe


WMDE allgemein
18. März 2022
Die App Scribe bietet Tastatur Erweiterungen für Sprachenlerner*innen. Die Tastaturen können in jeder App verwendet werden und ermöglichen es den Nutzer*innen zu kommunizieren, ohne für die Grammatikhilfe zu anderen Apps zu wechseln. Die App nutzt lexikografische Daten aus Wikidata, um Tastaturen für Französisch, Deutsch, Italienisch, Portugiesisch, Russisch, Spanisch und Schwedisch zu erstellen. Wir sprachen mit Andrew McAllister, der Scribe entwickelt hat. Andrew wollte sein eigenes Lernen erleichtern, und ermöglicht das gleiche nun vielen anderen durch seine Open Source App.
Bitte stelle dich mit ein paar Worten vor:
Ich komme ursprünglich aus Oregon in den USA und lebe jetzt seit fünf Jahren in Berlin. Ich bin nach Deutschland gekommen, um einen Master in Wirtschaftswissenschaften und Management zu machen, und habe während meines Studiums zu Data Science gewechselt. Nach meinem Abschluss habe ich neben meiner freiberuflichen Tätigkeit und persönlichen Projekten an Wikimedia Projekten mitgearbeitet.
Wie bist du auf die Idee von Scribe gekommen?
Scribe ist meine Lösung für meine eigenen Schwierigkeiten beim Deutschlernen. Ich bin englischer Muttersprachler, spreche Spanisch und habe ein recht gutes Verständnis von Chinesisch, da ich auch in China gelebt habe. Als ich anfing, Deutsch zu lernen, merkte ich, dass die Grammatik sehr komplex ist. Ich habe viele Deutschkurse besucht, und meine Lehrer*innen schlugen vor, Substantive farblich zu kennzeichnen, damit man sich ihr Geschlecht besser merken kann. Mir wurde klar, dass es großartig wäre, wenn ich eine App hätte, die mir dies im alltäglichen Gebrauch abnehmen würde. Von da an entstand die Idee zu Scribe.
Scribe verfügt derzeit über Tastaturen für Französisch, Deutsch, Italienisch, Portugiesisch, Russisch, Spanisch und Schwedisch. Alle Funktionen beruhen auf den lexikografischen Daten, die auf Wikidata verfügbar sind.
So funktioniert Scribe:
Zuerst öffnet man die Scribe-Tastatur auf dem Handy in einer App wie WhatsApp oder Signal. Scribe kann auch in E-Mail-Apps verwendet werden, oder überall, wo man eine Tastatur benötigt.
Bei Substantiven tippt man das Wort ein, drückt die Leertaste und dann zeigt Scribe die Wortform an. Die Farbe und der Vermerk zeigen das Geschlecht an oder ob es sich um den Plural handelt.
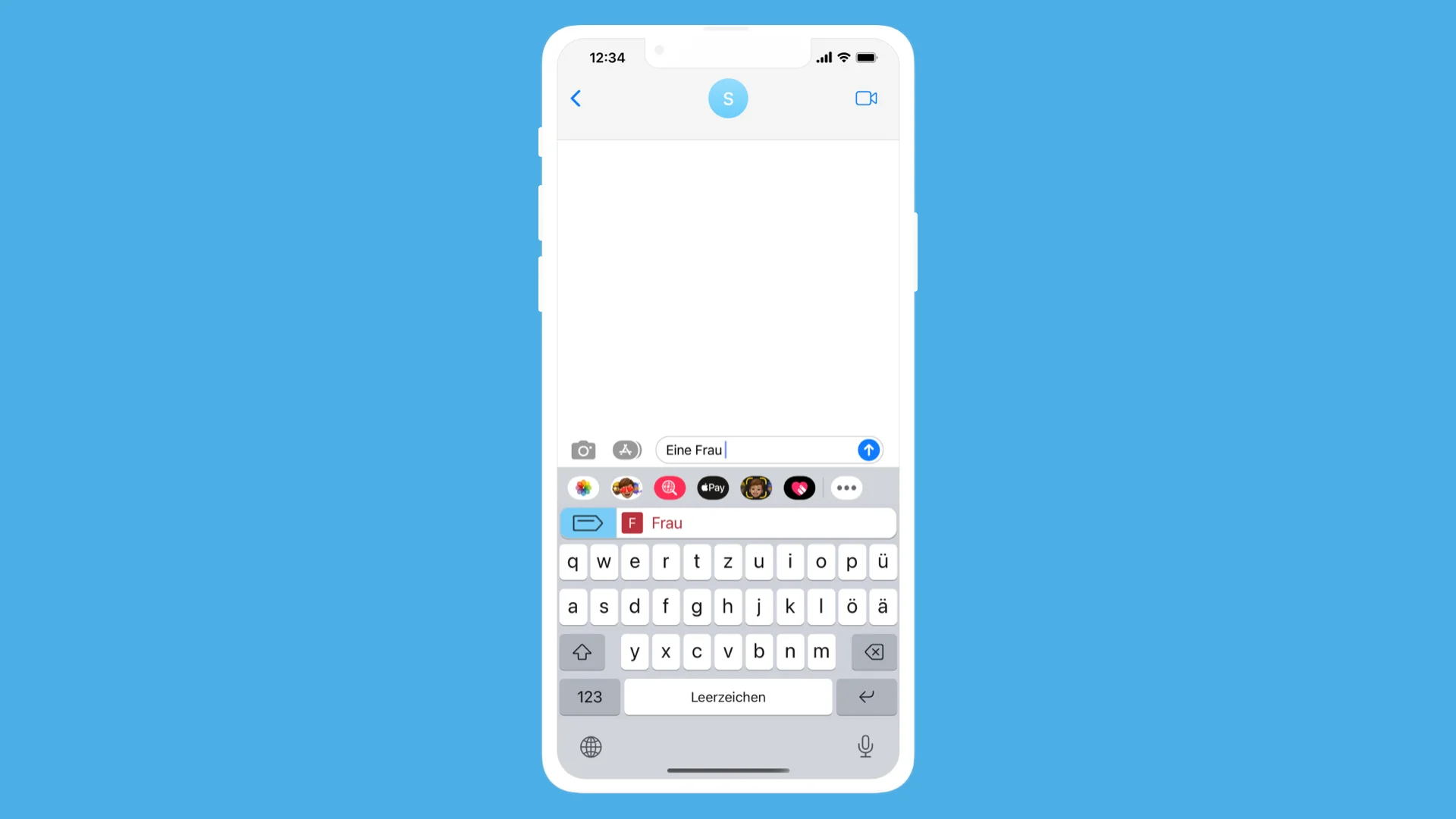
Ähnlich verhält es sich mit Präpositionen: Nachdem man die Leertaste gedrückt hat, zeigt Scribe an, welcher Fall folgen muss. Wenn eine Präposition mit mehr als einem Fall verbunden ist, wird dem Benutzer jeder Fall angezeigt.

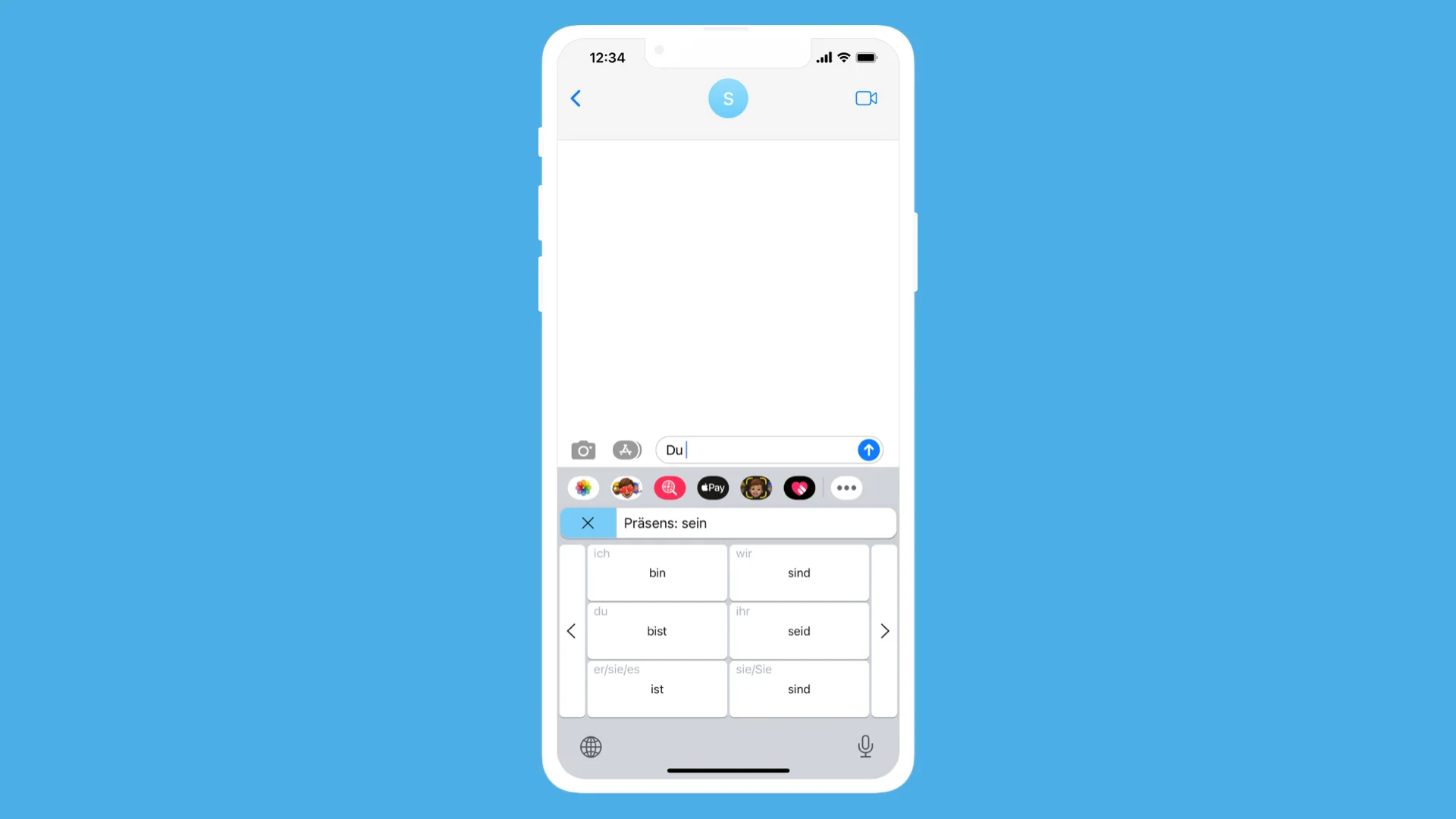
Wenn man die Scribe-Taste oben links drückt, können drei Optionen ausgewählt werden: Übersetzen, Konjugieren und Plural. Wenn eine dieser Optionen ausgewählt ist, kann man ein Wort in die Befehlsleiste eingeben und die Eingabetaste drücken, um den Befehl auszuführen. Speziell für Konjugation wird durch Drücken der Eingabetaste eine Konjugationstabelle angezeigt, in der das Klicken auf eine Konjugation sie in das Textfeld einfügt.
Wie funktioniert Scribe auf der technischen Seite?
Zunächst war es sehr einfach, mit Wikidata zu arbeiten! Zu Beginn dieses Projekts habe ich gelernt, wie man Wikidata Query Service-Abfragen anhand der Beispielabfragen für lexikografische Daten durchführt. Ich habe auch einige Fragen gestellt und die Wikidata-Community war sehr hilfsbereit.
Der gesamte Prozess ist jetzt sehr einfach. Ich habe SPARQL-Abfragen gespeichert, die mir alle Substantive, Verben und andere Wortarten für jede Sprache liefern, die Scribe unterstützt. Die Ergebnisse dieser Abfragen werden dann als JSON-Dateien gespeichert, die in der App selbst referenziert werden.
Das Speichern der Daten in der App bedeutet, dass Scribe keine Internetverbindung benötigt, und sehr reaktionsschnell ist. Glücklicherweise ist JSON ein sehr kompakter Dateityp, wobei die gesamte App weniger als 50 Megabyte groß ist. Das ist wirklich super, wenn man bedenkt, dass 195.000 russische Substantive mit all ihren Informationen, die Konjugationen für 3.200 deutsche Verben und all die anderen Daten, die Scribe bereits über Wikidata hat, in der App enthalten sind.
Die Übersetzung ist die einzige Funktion, die nicht zu 100% auf Wikidata basiert. Momentan verwendet dieses Beta-Feature maschinelle Übersetzungen, die ich in Python erstellt habe, da Wikidata nicht viele Übersetzungen enthält. Hoffentlich können wir irgendwann die Übersetzungen von Wiktionary übernehmen. Ich habe gesehen, dass es dort tonnenweise Übersetzungen in allen Sprachen gibt. Englisch ist bislang die einzige Ausgangssprache, aber das wird hoffentlich bald auf andere Sprachen ausgeweitet. Ein großes Ziel ist es, dass Benutzer*innen Scribe nutzen können, indem sie nur Daten aus Wikidata verwenden.
Welche Tools und Werkzeuge hast du für die Entwicklung von Scribe verwendet?
Ich verwende das Python-Paket WikidataIntegrator für die Datenaktualisierung. Die Bibliothek ermöglicht es mir, alle SPARQL-Skripte, die ich auf Wikidata gespeichert habe, zu laden, so dass ich in nur einer Python-Datei alle Abfragen ausführen und die Daten innerhalb von 15 Minuten aktualisieren kann. So einfach ist es für mich, alle Substantive, Verben und andere linguistische Daten für eine Scribe-Veröffentlichung zu aktualisieren.
Die App ist komplett kostenlos und open source. Warum haben Sie sich dafür entschieden?
Das Schwierige bei der Entwicklung einer App wie dieser ist die Beschaffung aller benötigten linguistischen Daten. Sprache ist so komplex. Wenn jemand – sagen wir ein Unternehmen – dies in seiner Vollständigkeit tun wollte, wäre das sehr schwierig. Aber mit offenen Daten von Wikidata und Open-Source-Beiträgen bin ich wirklich zuversichtlich, dass Scribe irgendwann ein sehr ausgereiftes Produkt sein wird. Das hat sich bereits bei einigen Datenaktualisierungen gezeigt, bei denen innerhalb weniger Wochen Tausende von vollständig konjugierten Verben hinzugefügt wurden!
Eine Open-Source-Anwendung, die auf Open-Source-Daten basiert ist einfach sehr agil. Wenn ich eine weitere Sprache zu Scribe hinzufügen möchte, muss nur ein Bot die Sprachdaten in Wikidata eingeben, jemand fügt Standarddateien hinzu, um die benötigten Schlüsselzeichen zu definieren, und am Ende der Woche gibt es ein neues Update und eine neue Tastatur.
Darüber hinaus ist die einzige Möglichkeit, mit einer App wie Scribe Geld zu verdienen, das Sammeln von Nutzer*innendaten, und das kam für mich moralisch nicht in Frage. Ich habe kein Interesse daran, die Textdaten von Menschen zu sammeln. Open-Source ist auch eine tolle Möglichkeit, in die Entwicklung einzusteigen. Scribe ist meine erste App, und es war eine großartige Lernerfahrung!
Auf welche Herausforderungen bist Du bei der Arbeit an Scribe gestoßen?
Von Zeit zu Zeit stoße ich bei Wikidata auf Abfragebeschränkungen. Im Moment ist das noch in Ordnung, aber wenn Scribe größer wird, könnte das schwieriger werden.
Außerdem sind die Daten, wie bei vielen Datenprojekten, oft nicht perfekt. Manchmal gibt es eine Vielzahl von Einträgen mit unterschiedlichen Taxonomien dahinter. An diesem Punkt berücksichtige ich einfach, dass es verschiedene Systeme zur Organisation der Daten gibt, wenn ich die Abfragen schreibe.
Welchen Rat würdest du anderen geben, die ähnliche Tools mit Wikidata bauen wollen?
Ein toller Tipp, den ich bekommen habe, war, bei der Suche in Wikidata „L:“ an den Anfang der Suche zu setzen, um nur lexikografische Daten zu erhalten. Es kann wirklich schwierig sein, Sprachdaten auf Wikidata zwischen all den anderen Informationen zu finden.
Wer offene Daten von Wikidata verwenden möchte, sollte ein Open-Source-Projekt in Erwägung ziehen, um zu Open-Source-Technologien beizutragen. Für mich ist das der beste Weg, um mich für die harte Arbeit zu bedanken, die in die Entwicklung von Wikidata geflossen ist. Unabhängig davon, ob Open-Source oder nicht, die Wikidata-Gemeinschaft zu kontaktieren war bisher wirklich sehr hilfreich.
Was sind die nächsten Schritte für Scribe?
Scribe ist derzeit nur für iOS verfügbar, aber es wäre toll, wenn es eine Android- und eine Desktop-Version geben würde. Die Android-Version würde wahrscheinlich in Kotlin geschrieben werden und die Desktop-Version in Python. Es wäre großartig, etwas Hilfe zu bekommen, und Interessierte sind herzlich eingeladen, den GitHub für Scribe zu besuchen!
Was die Daten angeht, so funktioniert Scribe derzeit hervorragend für Deutsch und Schwedisch, die sehr robuste Daten haben, aber wir brauchen mehr Verben auf Wikidata – speziell für Russisch, Italienisch und Französisch. Die Erweiterung der Übersetzungsfunktion auf die lexikographischen Daten von Wikidata wäre ein großer Schritt, und das Hinzufügen anderer Funktionen wie Autovervollständigung und Autokorrektur sind ebenfalls eine Priorität.
Darüber hinaus versuche ich, mehr Mitwirkende für Scribe und Wikidata zu gewinnen. Ich habe gerade einen Vortrag über Scribe bei den Wikidata Reuse Days 2022 gehalten und fange an, Sprach-Communities und andere zu erreichen, die Interesse haben könnten. Wir stehen noch am Anfang mit Scribe, und ich bin wirklich begeistert, dass es bereits so viel Interesse daran gibt.



