
Wikibase and the Enlightenment
Modeling the Enlightenment novel: an interview with the MiMoText team


Christos Varvantakis
28. June 2024
Today we present our chat with the Trier Center for Digital Humanities, University of Trier, about their MiMoText project: an innovative initiative in the study of literary history. Focusing on the French Enlightenment novel, MiMoText (“mining and modeling text“) leverages advanced text-mining techniques to extract and model information from an array of sources, including 18th-century texts and contemporary research literature. MiMoText then uses Wikibase to integrate this varied data into a cohesive, multilingual knowledge base that’s linked to external resources such as Wikidata. In this interview, the team members share with us how MiMoText puts Wikibase to use enhancing data accessibility and interoperability (including performing federated queries across multiple databases) and discuss broader implications for the digital humanities.
Please provide us an overview of the MiMoText project and its objectives.
MiMoText is a research project in computational literary studies involving new ways to model and analyze literary history — specifically the French Enlightenment novel. It’s based on the idea of extracting relevant statements from a wide range of sources (such as bibliographic resources, primary texts from the 18th century, and current research literature) in order to build a shared knowledge network for literary history.
“MiMoText” is short for “mining and modeling text”; we use information-extraction and text-mining methods on our data to extract a large quantity of statements about authors and literary works. By modeling the data in the Linked Open Data paradigm, we link this heterogeneous information to form a common knowledge base, interconnected both internally and with external knowledge resources, particularly Wikidata.
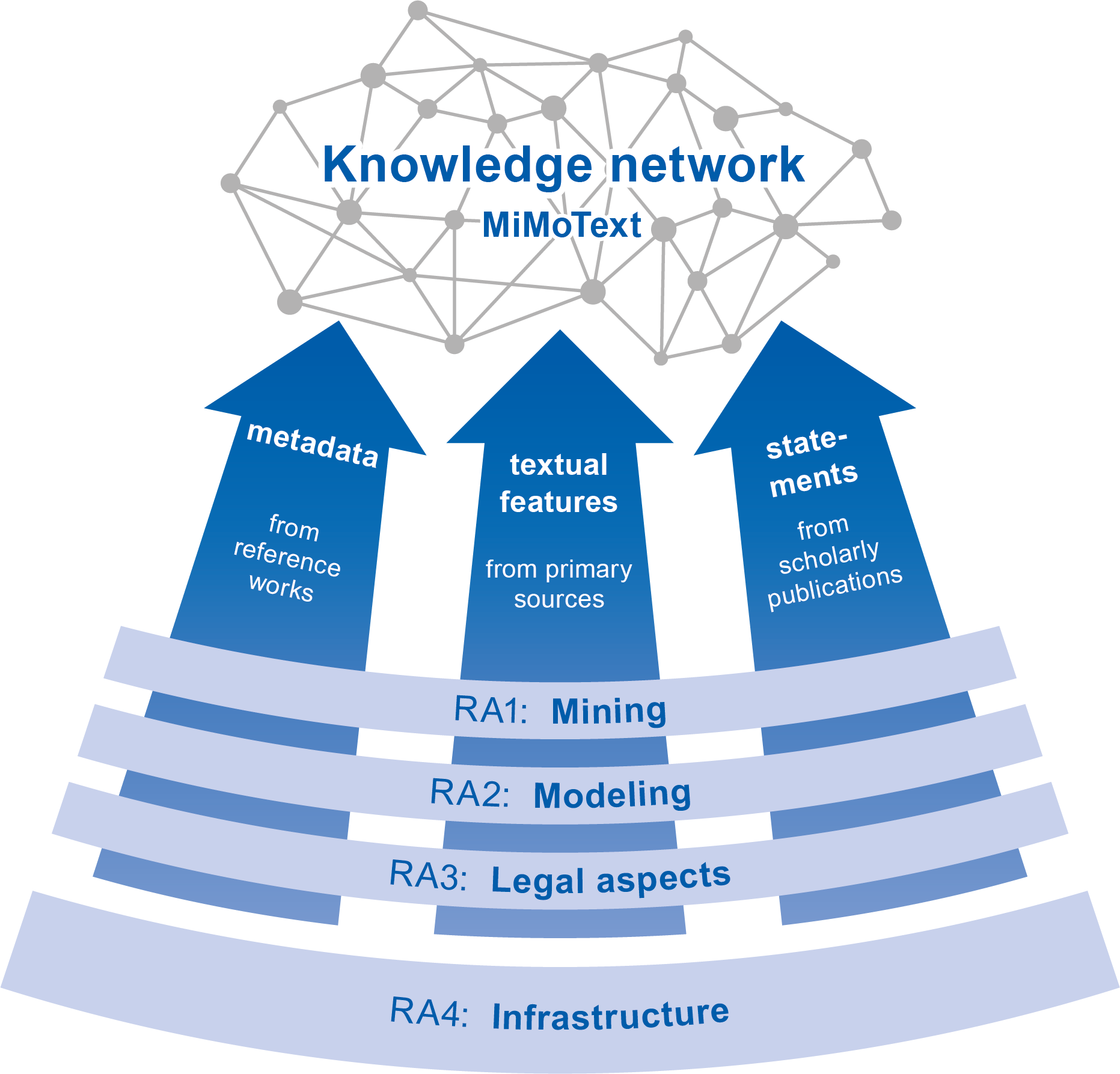
Overview of the project structure with four research areas:
mining, modeling, legal aspects and infrastructure
How did you decide to use Wikibase for the MiMoTextBase?
At the start of the project, we compared several tools for creating knowledge graphs, using open science principles in creating both the data provision and the infrastructure for the project.
- First of all, we felt it was important to use free, open-source software that is user-friendly and has a committed community.
- We also found the ability to handle multilingual data persuasive; we wanted to integrate data from French novels as well as German scholarly literature and to make the data available in English.
- Wikidata’s flexible data model seemed very useful for us in our attempt to reference complementary information gained from different source types and also to represent contradictory statements at the same time. We found quite convincing the complex but differentiated system provided for referencing and qualifying statements: “claims”.
- Furthermore, the structure of the knowledge network in the Linked Open Data paradigm is closely linked to the query options. The SPARQL endpoint (the interface to the Wikibase Query Service) is very useful and offers some great possibilities such as the ability to store example queries, various query templates, etc.
- Above all, however, we were excited about the built-in data visualization possibilities. The project would not have had the resources to develop such analysis and exploration options.
We see the MiMoTextBase as part of the Wikibase ecosystem, which is constantly growing. There were two very pleasing developments that we couldn’t have fully anticipated at the beginning of the project. In addition to the ability to link Wikibase instances, another important dimension is the current development of the tool suite: for example, we used OpenRefine for reconciliation, mapping text strings from our sources (e.g., places in novels) to Wikidata items.
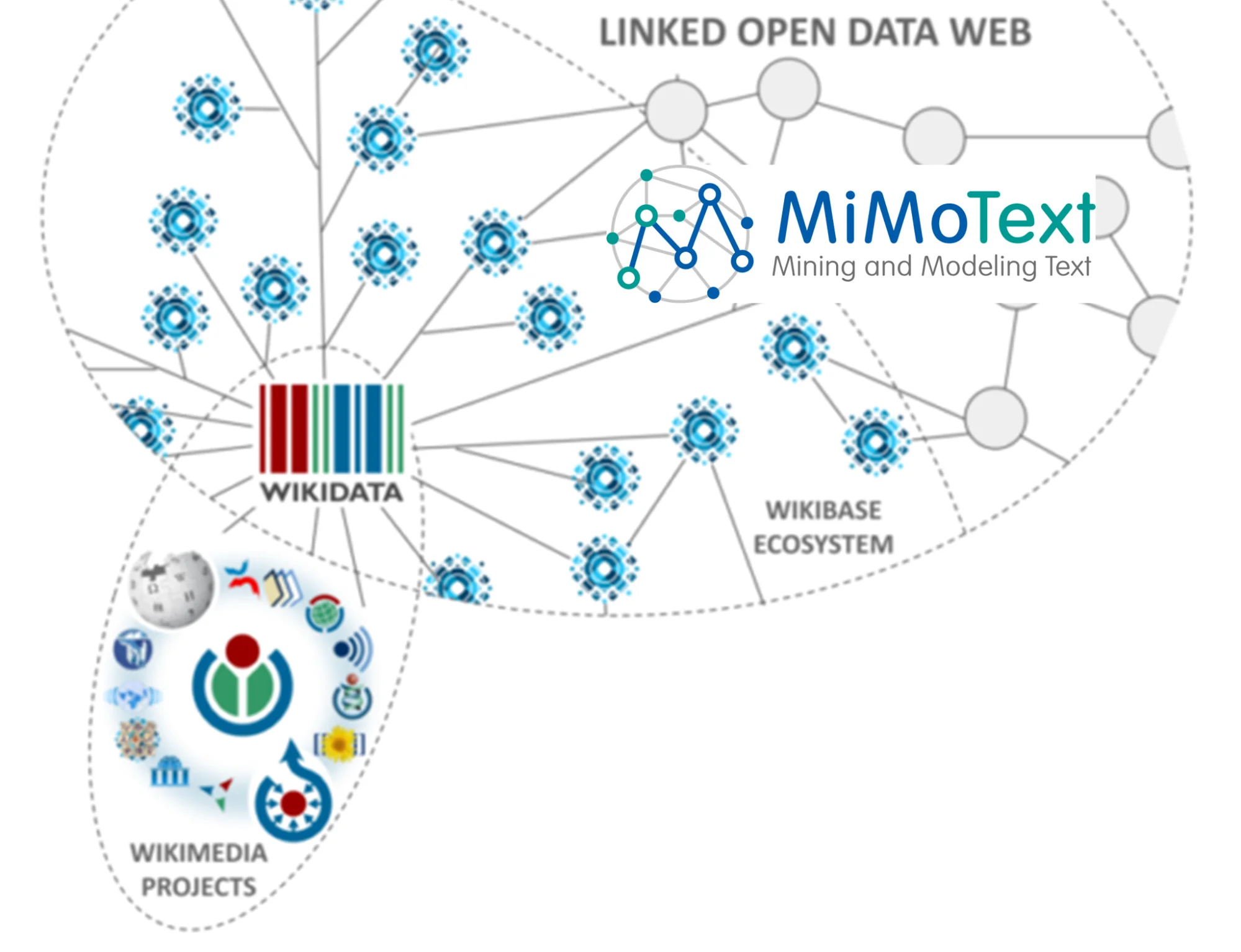
A view of the MiMoTextBase within the Wikimedia Linked Open Data web.
Credit original visualization: Manuel Merz.
How does Wikibase enhance the interoperability of data in MiMoTextBase? What’s the role and significance of Wikibase features around multilingual labeling in your knowledge base?
As outlined before, various methods in MiMoText combine and generate different statements from completely different types of sources. In total, the MiMoTextBase contains around 330,000 statements and is the place where everything gets integrated while remaining fully retraceable. All statements are referenced and linked to sources, specific data sets and methods. If you’re interested in how we generated statements about the themes, locations and styles of 18th century novels based on topic modeling, named entity recognition and stylometry (methods frequently used in the field of digital humanities), you can delve into the associated GitHub repositories.
Multilingual vocabularies were very important for the project’s aforementioned multilingual dimension, particularly for linking sources from different languages. These vocabularies are also part of our MiMoTextBase; if you find that interesting, you can access further information in the associated repository.
In MiMoTextBase you’ve enabled federated queries between your knowledge base and Wikidata. Could you explain what these are, and how you’re facilitating these queries?
We began with federation starting from our MiMoTextBase in the direction of Wikidata. The fundamental advantage of federation is that you don’t have to store data redundantly in several places but can make queries across several databases. These are called federated queries. To enable them, we matched the identifiers of our MiMoTextBase with Wikidata’s corresponding identifiers, such as “people” or “places”. In this way, by matching their names you can query authors’ birth dates, which we don’t store locally in the MiMoTextBase but which are available in Wikidata.

Federation between MiMoTextBase and Wikidata
We also matched the spatial identifiers, which means we can survey the locations of the novels, opening up the possibility of querying geocoordinates from Wikidata (example query). Furthermore, we can combine very different individual queries. For example, we can query which locations in novels are frequently linked to certain topics, such as travel.

An example of a federated query:
narrative locations of French novels 1751–1800 by theme
In addition to allowing MiMoText users to employ information from the huge Wikidata knowledge graph using federated queries, we’ve also recently enabled querying in the other direction. We imported into Wikidata a portion of our data that’s relevant to the public and linked it to our MiMoTextBase by means of the MiMoText ID, an external identifier that we proposed to Wikidata. Users seeking detailed information about Enlightenment novels can query it via the Wikidata Query Service as demonstrated in this example query. For deeper insight into the process as well as some more federated queries, take a look at our documentation. The following visualization gives a rough idea of the links between the two knowledge graphs.

Overview of links between MiMoTextBase and Wikidata
Could you describe the process of setting up your own SPARQL endpoint and its significance for your project?
The SPARQL endpoint is crucial. On the one hand, there is a SPARQL endpoint API suitable for advanced users who want to further process the data or the query results. On the other hand, we have the Wikibase Query Service interface which, as previously mentioned, offers numerous options and formats for exporting, analyzing and visualizing queries and their results. We find these options very useful, even for less experienced users, in exploring the data and recognizing patterns that confirm or contradict certain assumptions; the options also open up completely new perspectives. It’s vital to allocate enough time and human resources for the setup and operation of a Wikibase instance. For projects that have few resources available, a workable alternative might be the Wikibase cloud service.
Were there challenges you encountered while working with Wikibase in the MiMoText project, and how did you address them?
We encountered a couple of challenges working with Wikibase. The various programming languages, frameworks and technical platforms and systems used in the Wikibase ecosystem entailed extra effort in customizing Wikibase with its various extensions. The documentation of the extensions and configuration options could have been more detailed in some cases. It does help that there is a lively community.
Two points may also be interesting for other projects. From today’s perspective, we would recommend installation using the Docker containers [known as Wikibase Suite]. Although some options are lacking, there is a great deal of simplification and a lot of built-in extensions. In addition, we spent a relatively large amount of time adapting our customized PyWikiBot; from today’s perspective, we can say that QuickStatements, which we recommend, would have been sufficient for the vast majority of our import scenarios.
What practices do you employ to ensure the sustainability of your Wikibase infrastructure?
The project ran from 2019 to 2023 at the Trier Center for Digital Humanities (TCDH), located at the University of Trier. We are one of the oldest digital humanities centers in Germany and can guarantee the sustainable availability of the MiMoTextBase in the coming years. We also regard sharing a relevant selection of our data in Wikidata as an important step towards sustainability. Furthermore, although the MiMoTextBase was the first, it will certainly not be the last Wikibase created at the Trier Center for Digital Humanities. The MiMoText project modeled the quite specific domain of the French Enlightenment novel; now we are transferring this approach to the broader domain of the humanities. Our project LODinG (Linked Open Data in the Humanities, running from 2024 to 2028) collects, analyzes and models data in the Linked Open Data paradigm across several sub-projects on very different subject areas, such as lexicographic data on historical pandemics, wine labels, and medical-botanical knowledge from the early modern period.
In your view, what role could Wikibase play in the broader landscape of digital humanities research? How might projects in the field benefit from the Linked Open Data web?
There are several advantages to Wikibase and to the Linked Open Data web as a whole. We see a kind of bridging function in the fact that Linked Open Data can be generated and analyzed using both qualitative and quantitative methods. This bridging is particularly important for the digital humanities; we still see a lot of untapped potential in this field. Wikibase’s interface (as well as the tool suite with OpenRefine, for example, and tools such as QuickStatements) supports qualitative work with smaller data sets as well as quantitative work with larger data sets and many things in between.
Being able to work collaboratively is of course another great advantage. Wikidata’s status as the largest Wikibase instance makes it a kind of hub for linking humanities data across project boundaries. The more projects in this ecosystem that share the same infrastructure, the denser and more significant the whole knowledge graph becomes. Of course, federated queries are possible across different types of infrastructures (via RDF and SPARQL as W3C standards), but they’re made easier by a common basic data model since it is shared via Wikibase. Ideally, researchers could use data from very different projects via federation if they were linked together.
Of course, there are also many challenges. For example, the matching process is quite time-consuming, and federated queries require precise knowledge of the various databases’ data models to be queried. In order to overcome the hurdle of needing to know SPARQL, it was important for us to share our knowledge in various workshops. In addition, we created a comprehensive online tutorial that introduces the SPARQL query language with many illustrative examples from our Wikibase instance.
Thank you for your time and for the fascinating insights into your Wikibase project!
In this interview we heard from:
- Maria Hinzmann, MiMoText team coordinator (research area: modeling), Trier Center for Digital Humanities
- Matthias Bremm, MiMoText team member (research area: infrastructure), Trier Center for Digital Humanities
- Tinghui Duan, MiMoText team member (research area: mining, scholarly literature), Trier Center for Digital Humanities
- Anne Klee, MiMoText team member (various research areas), Trier Center for Digital Humanities
- Johanna Konstanciak, MiMoText team member (various research areas), Trier Center for Digital Humanities
- Julia Röttgermann, MiMoText team member (research areas: mining, novels), Trier Center for Digital Humanities
- Christof Schöch, MiMoText project lead and co-director of Trier Center for Digital Humanities
- Joëlle Weis, head of the research area Digital Literary and Cultural Studies, Trier Center for Digital Humanities

