Unveiling discrepancies: First experiences with finding mismatches on Wikidata and how you can too
Purdue Data Mine with WMDE

The project
In spring 2024, Wikimedia Deutschland began a partnership with the Corporate Partners Program in Purdue University’s Data Mine, a learning community where students perform data-driven research to create solutions to real-world problems. In the Corporate Partners Program, students collaborate with corporate mentors to complete their task.
We’re a team of five students from different majors. As part of the collaboration project, we identified mismatches for the Wikidata Mismatch Finder, a tool conceived and built by Wikimedia Deutschland (WMDE) that allows users to report errors and disparities in Wikidata.
Wikidata is an online knowledge base that can be read and edited by both humans and machines. As of this writing it contains 112 million data items to date; with over two billion edits, it is by far the most edited of all the Wikimedia projects. Wikidata serves as a central storage area for other Wikimedia sister projects, including Wikipedia, Wikivoyage and more. It also provides data for many applications outside Wikimedia, very likely including your smartphone’s digital assistant.
In this project, we looked for mismatches between Wikidata and other external sources, using Python to compare the data values and examine whether or not they match. Mismatches result in a Mismatch Finder entry and a message on the Wikidata item’s page that requires a closer look by a human.
The current version of the Mismatch Finder is not widely used; this project serves as a good testing stage for potential improvements, which will allow more community members and external organizations to share their mismatches.
Mismatch Finder
Not all information on Wikidata is accurate. Because many everyday applications like Wikipedia, search engines and artificial intelligence all use Wikidata’s data, these inaccuracies represent a significant issue; incorrect data from Wikidata can be picked up by these downstream projects, leading to the spread of false information.
To address this issue, Wikimedia Deutschland created the Wikidata Mismatch Finder, which allows downstream projects and the broader Wikimedia community to report disparities between Wikidata’s data and other trusted data sources. If a Wikidata entry lists a book’s publication date as 1996, but another data source lists the publication date as 1998, the entry would be considered a mismatch and would require human review to fix or at least note the disparity.
Mismatches in the Mismatch Finder UI appear as follows:
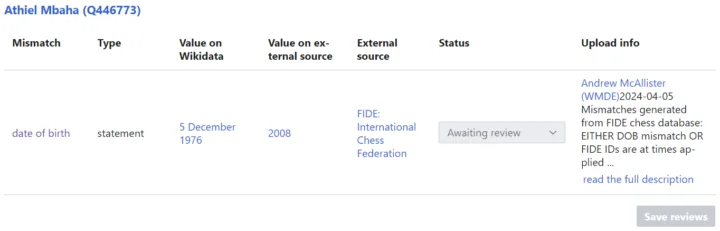
The interface helpfully displays the mismatched property in question, Wikidata’s own value, the external source’s value, and the external source link for checking the mismatch. Users can then review uploaded mismatches and decide which value is correct. A banner will appear prompting the user to fix information that conflicts with external sources. For more information, visit the Wikimedia Mismatch Finder documentation.

Above you can see an example of the banner displayed on Wikidata items with mismatches. After enabling the Mismatch Finder gadget in their preferences, users can click the provided link to see further details of the mismatch.
The workflow
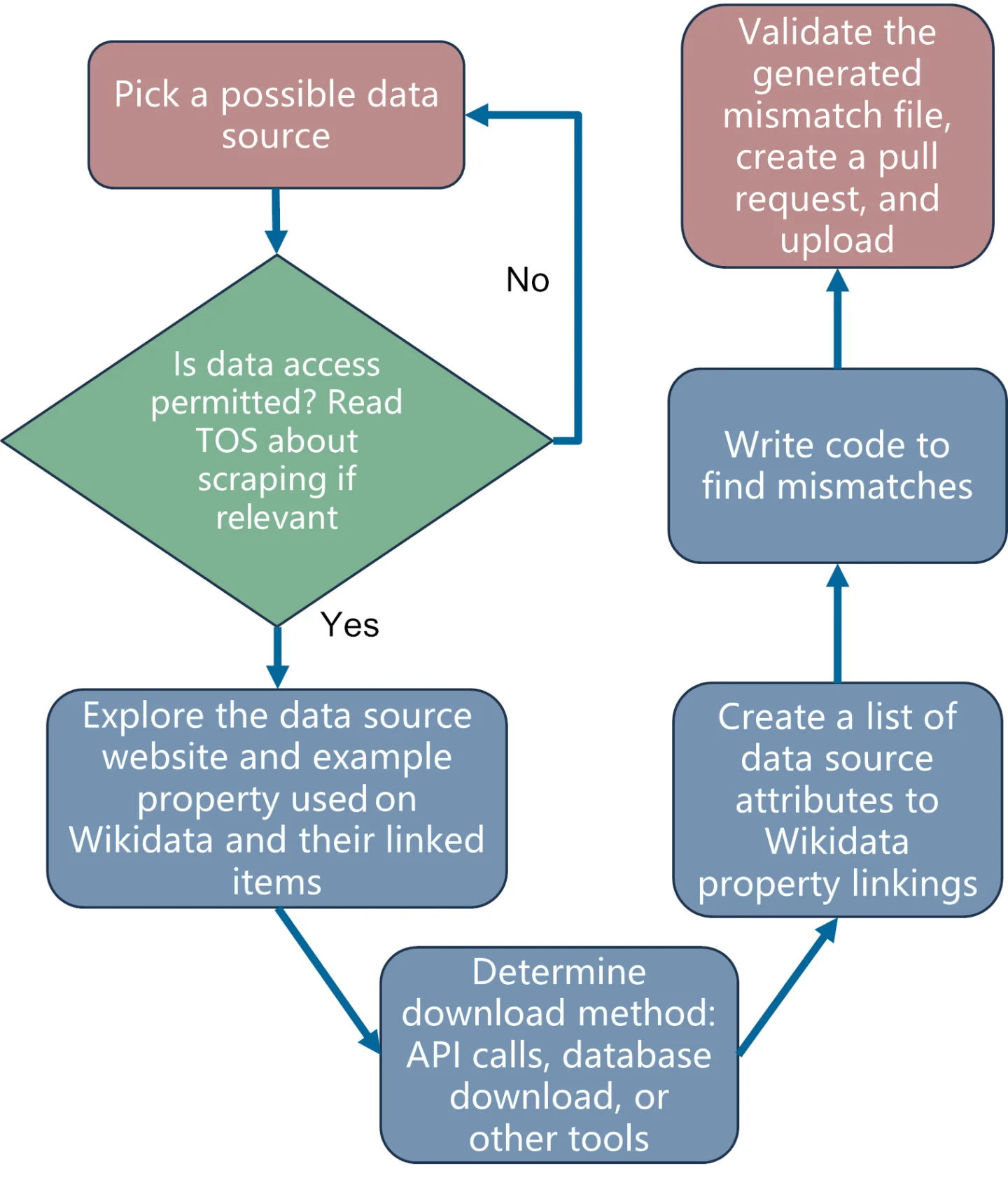
In identifying mismatches we follow the general process shown above. We start by looking at various data sources to see which are best suited for examination. For any data source, we ask two questions. First, can the source’s data legally be used for our purposes? (If the source prohibits web scraping, for example, we wouldn’t use it.) Second, is the data accessible to users, such as through APIs, data dumps, or web scraping? If the answer to both questions is yes, we proceed to the next step.
Once we’ve chosen a data source, we then determine which properties we can use. We often use quantitative properties (e.g., P569: birth date, P570: death date) because their format makes them easier to compare than qualitative properties (e.g, P27: country of citizenship, P19: birthplace) which can take varying forms. Additionally, we ensure that the data within the source itself is specific: the Wikidata property must contain a value, and we avoid data with long descriptions or undefined texts.
Once we’ve chosen the data source and property, the next step is to determine how to obtain the data. One option is to use API calls, automated web requests. Other options include data dumps and web scraping. Then we create a list of source data linked to Wikidata and write code that joins the data, compares the various points in common, finds the mismatches, and formats them all in a CSV file made just for the Mismatch Finder. Finally, we upload the CSV to the Mismatch Finder in 10MB chunks. (Consult the GitHub repository for all the project code and our detailed example Jupyter notebooks showing the steps we took to generate our mismatch files. We’ve also included Python scripts to help you upload your mismatch files once prepared.)
After the mismatches have been generated, the final step of the process involves validating and cross-checking our results with other team members and our mentors at Wikimedia Deutschland to ensure that the mismatches met the upload criteria and didn’t contain any major flaws.
Our results

We chose six external data sources to compare against Wikidata. Then we scrutinized a specific property for each source and generated our mismatches. The table above depicts the percentage of entries that resulted in mismatches for each data source. FIDE, the International Chess Federation, had over 22,000 corresponding Wikidata items, 120 of which had mismatched birth year values. The National Gallery of Art had a 16% mismatch rate for dates of birth and death. MusicBrainz had only a 6% property mismatch rate for date of birth, date of death and inception date, but Find-a-Grave had a whopping 30% of mismatches on properties for date of birth, date of death, burial location, burial plot, place of birth and place of death.
Recap and next steps
The goal of the Wikimedia Deutschland collaboration project with Purdue Data Mine was to identify and address differences between Wikidata and external data sources. We successfully created mismatches and learned the process, and WMDE learned how easy the various parts of the Mismatch Finder are to use. Thanks to all participants contributing to their mismatches, the collaboration project met its goal.
The project benefited both WMDE and Purdue Data Mine. WMDE introduced the process of generating mismatches to a wider audience, and they were able to test the Mismatch Finder, a product in its early stages. The current version of the Mismatch Finder is not widely used; this project serves as a good testing stage for potential improvements, which will allow more community members and external organizations to share their mismatches. As for us students, we learned how to contribute to an open-source project and gained real-world experience not only in various data collection methods but in Python programming generally.
All of the work in this project is open source and released under open licenses. We hope it will encourage people interested in contributing to Wikidata. The project made available many resources to help showcase the process of generating mismatches for the Mismatch Finder, allowing people with no prior experience to get through the learning curve.
Wikidata is an important resource for the web. Many projects use Wikidata and other data sources; the accuracy of Wikidata’s information is crucial. Maintaining the open-source ecosystem helps keep knowledge accessible. By contributing to Wikidata’s accuracy and completeness, you and others like you can build a robust foundation for future discoveries and advancements.
No comments yet
Leave a comment