Lexicographical Data for Language Learners: The Wikidata-based App Scribe
WMDE allgemein

The App Scribe offers iOS keyboard extensions for language learners. Scribe keyboards can be used in any app, and allow users to confidently communicate without switching to other apps for grammar help. The app uses lexicographical data from Wikidata to make keyboards for French, German, Italian, Portuguese, Russian, Spanish and Swedish. We talked to Andrew McAllister, who has built Scribe to support his own language learning and aims to share this tool with many others.
Please introduce yourself in a few words:
I’m originally from Oregon in the US, and have been living in Berlin for five years now. I came to Germany to do a Master’s degree in Economics and Management science, and switched to data science during my studies. Post graduation I’ve been working on my development skills along with freelance work and personal projects with Wikimedia.
How did you come up with the idea for Scribe?
Scribe is my solution to how difficult German is for second language learners. I’m a native English speaker, speak Spanish and have a fairly good understanding of Chinese from also living in China. When I started learning German, I realized that the complex grammar makes the language very hard to master. I’ve done a lot of German classes, and something that many teachers suggested was color coding nouns to help remember their genders. I realized that it would be great if I had an app that would do this for me in everyday conversations, and from there the idea grew to what it is today.
Scribe currently has keyboards for French, German, Italian, Portuguese, Russian, Spanish and Swedish. All its features are based on the lexicographical data that is available on Wikidata.
This is how Scribe works:
First you open a Scribe keyboard on your phone in an app like WhatsApp or Signal. Scribe can also be used in email apps or anywhere else where you’d need a keyboard.
For nouns, you type in the word, hit the space button, and then Scribe shows you what the word form is. The color and annotation indicate the gender or if it’s plural.
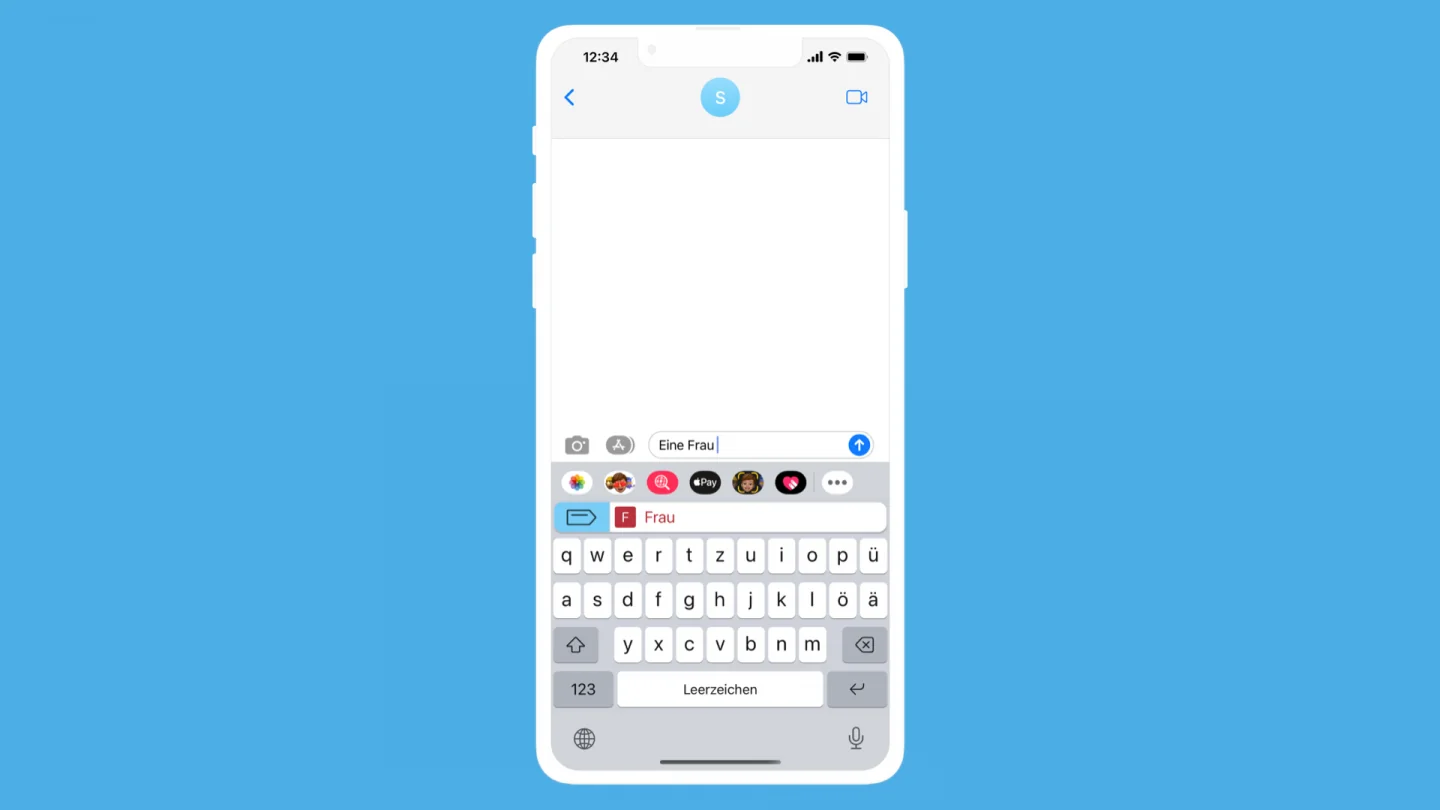
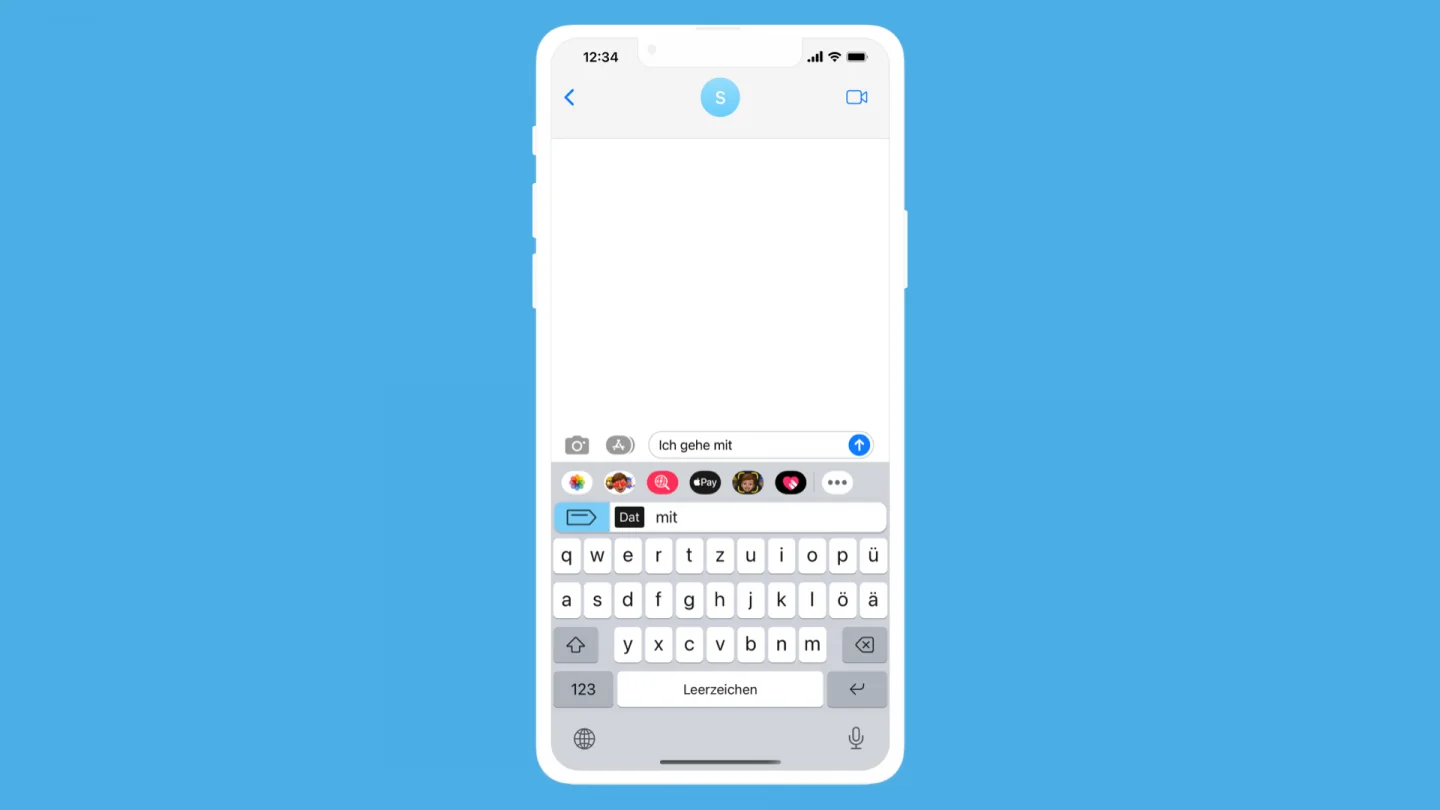
Similarly for prepositions, after hitting space Scribe will tell you what case will follow. If a preposition goes with more than one case, then each is presented to the user.
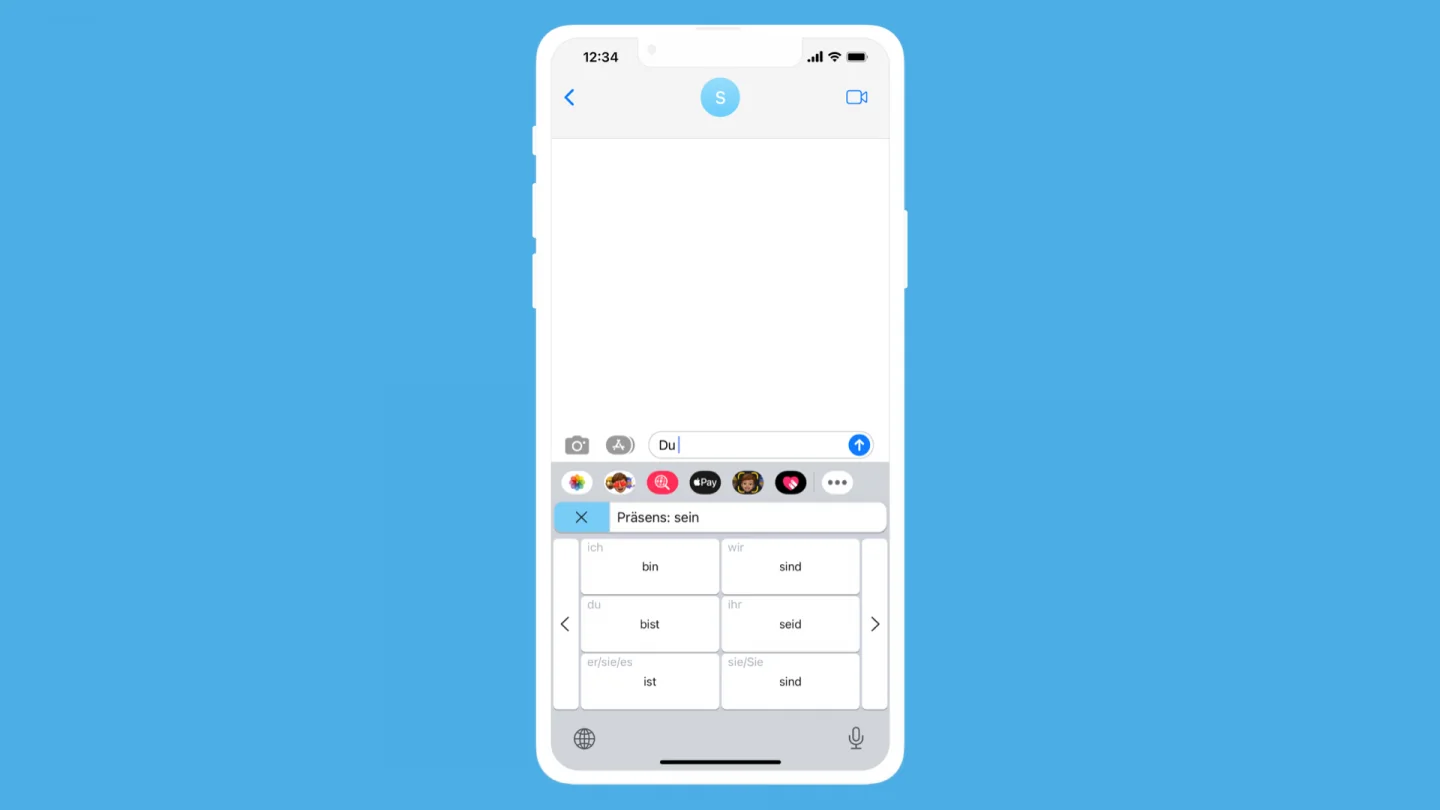
Pressing the Scribe key on the top left also gives you three selectable options: translate, conjugate, and plural. Selecting one of these options lets you enter the word in the command bar and press enter to execute the command. Specifically for conjugation, pressing enter brings up a conjugation table where clicking a conjugation inserts it into the text field.
How does Scribe work on the technological side?
I’m so impressed with how easy it is to work with Wikidata! At the beginning of this project I learned how to do Wikidata Query Service queries based on the example queries for lexicographical data. I also asked some questions and the Wikidata community was very supportive. The whole process is very streamlined at this point. I have SPARQL queries saved that give me all of the nouns, verbs and other word types for any language that Scribe supports. The results of those queries then get saved as JSON files that are referenced within the app itself.
Saving the data in the app means that Scribe doesn’t need an internet connection to work and is very responsive. Thankfully JSON is a very compact file type, with the entire app being less than 50 megabytes. This really is something when you consider 195,000 Russian nouns with all their information, the conjugations for 3,200 German verbs, and all the other data that Scribe already has via Wikidata.
Translation is the only feature that’s not 100% Wikidata based. Currently this beta-feature uses machine translations I did in Python, as Wikidata doesn’t have many translations. Hopefully we can migrate translations from Wiktionary at some point, as I saw that they have tons of translations across all languages. English is also the only source language, but hopefully this will expand to other languages soon. A big goal for this project would be that users can use Scribe to translate across many languages using just Wikidata sourced data.
What tools have you used to develop Scribe?
I’m using the Python package WikidataIntegrator for the data updates. The library allows me to load all the SPARQL scripts I have saved to Wikidata, so in just one Python file I run all the queries and update the data within 15 minutes. That’s literally how easy it is for me to update all of the nouns, verbs, and other linguistic data for a Scribe release.
The App is free and open source. Why did you decide to do that?
The difficult part in building an app like this is getting all of the linguistic data needed. Language is so complex. If someone – let’s say a company – wanted to do this in its completeness, it would be very hard to do. But with open data from Wikidata and open-source contributions, I’m really confident that at one point Scribe will be a very mature product. This has already been seen in some data updates where thousands of fully conjugated verbs have been added in a matter of weeks!
It’s also hard for me to think of a situation that is more agile than an open-source app based on open-source data. If I want to add another language to Scribe, all that really needs to happen is a bot puts language data into Wikidata, a Scribe contributor adds standard files to define the needed key characters, and then at the end of the week there’s a new update and a new keyboard.
Beyond this, the only way that you can make money off of an app like Scribe is to collect user data, and that morally wasn’t an option for me. I have no interest in collecting people’s text data. Open-source is also just a great way of getting into development. Scribe is actually my first app, and it’s been a great learning experience!
What challenges did you encounter while working on Scribe?
From time to time I run into rate limits on Wikidata. For now it’s fine, but it might get to a point where it’s a little bit more difficult when Scribe is scaled up and we are querying all of the translations of words for a certain language into 15 other languages.
Also, as is the case with many data projects, the data is often not perfect. Sometimes there are multiples of entries with different taxonomies behind them. At this point, I just take into account that there are different systems of organizing the data when I write the queries.
What advice would you give people who want to build similar tools with Wikidata?
A great tip I got was when searching Wikidata, putting “L:” at the start of your search gets you only lexicographical data results. It can be really hard to find language data on Wikidata through all the other information.
More broadly, if you are using open data from Wikidata, consider doing an open-source project to contribute to open-source technologies. To me that’s the best way to show gratitude for all the hard work that’s gone into making Wikidata. Regardless of open-source or not, my suggestion would be to not be worried about reaching out to the Wikidata community. They really have been very helpful so far.
What are the next steps for Scribe?
Scribe is currently only available for iOS, but it would be great to have Android and desktop versions. The Android version would likely be written in Kotlin, and the desktop version in Python. It’d be great to get some help, and those interested would be welcome to visit the GitHub for Scribe!
Data wise, Scribe is currently working great for German and Swedish that have very robust data, but we need more verbs on Wikidata – specifically for Russian, Italian and French. Expanding the translation feature to just use Wikidata lexicographical data would be a huge step, and adding other features like autocomplete and autocorrect are also a priority.
Beyond all this I’ll be spreading the word and trying to get more contributors for Scribe and Wikidata. I just gave a talk on Scribe at Wikidata Reuse Days 2022, and am starting to reach out to language learning communities and others that might have interest. It’s still very early for Scribe, and I’m really excited that there’s already so much interest in it.
No comments yet
Leave a comment